研究理念
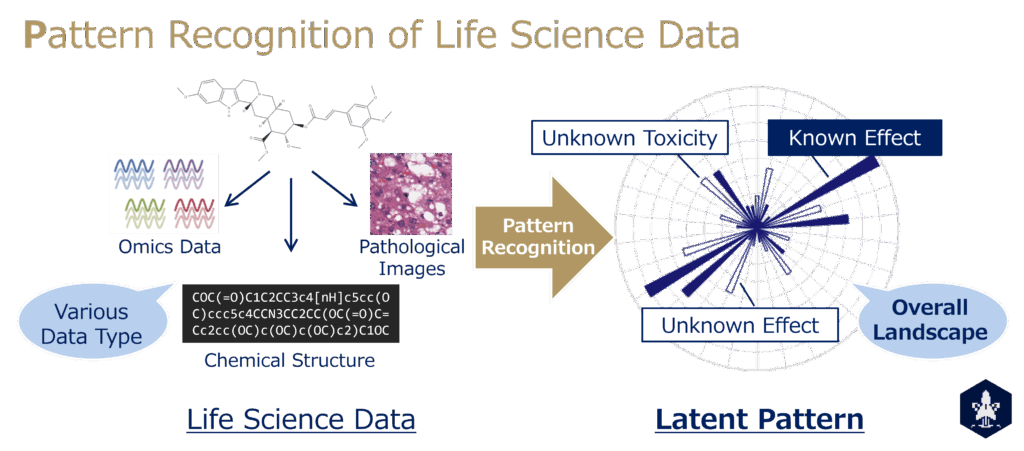
予期せぬ有害事象による市場撤退やドラッグリポジショニングの成功は, 医薬品がしばしば開発者すら想定していない未知の側面を明らかにしている。我々の研究は, この「認識されていない側面」を体系的に捉えることを目的とし, 生命科学データのパターン認識を基盤としている。すなわち, オミクスデータ, 化合物構造, 毒性病理画像, 科学論文といった多様なデータから潜在的かつ本質的なパターンを抽出し, 数理的に表現・可視化することで, 医薬品の性質を包括的に理解しようとするものである。
その際に重要となるのが, 恣意性を最小化したデータ取得である。これには二つの軸がある。第一は網羅性のあるデータであり, 代表例としてオミクス解析が挙げられる。特定のレイヤーに属する変数を余さず取得することで, 少なくともその層において偏りの少ない数値化が可能となる。第二は感覚器に近いデータであり, 代表例が画像データである。画像は取得段階で人間の主観をほとんど介さないため, 恣意性の少ない数値情報を得ることができる。 一方, こうしたデータは冗長性や不変性を内包しており, 単純な処理だけでは本質的な特徴を抽出することが難しい。ここで重要となるのがパターン認識である。深層学習による潜在表現の抽出や, 統計学的枠組みに基づく潜在変数モデルなど多様な手法を駆使し, データの背後に潜む構造を俯瞰的に捉える営みであり, これこそが我々の研究対象である。「どのような入力(データ)に対して, どのような手法を用いることで, どのような出力(パターン)が得られるのか」という問いを明示的に探求している。
これまでにin vitroでのトランスクリプトーム解析を通じて戦略の有効性を示し (Nemoto S., J Nat Prod., 2021), 現在はin vivoやin humanへと展開している。近年の成果は, オミクス, 毒性病理画像, 化合物構造, テキストといった多様なデータを対象に, 医薬品の未知側面を抽出する方法論の確立へと発展しつつある (Morita K., Toxicol Sci., 2023; Maedera S., Comput Biol Med., 2024; Yoshikai Y., Nat Commun., 2024)。この一連の研究は, 人間の認識を拡張し, 知見の社会的定着を促す普遍的な枠組みとなることを目指している。
教育方針
我々は研究だけでなく, 未来の研究者を育てることも重視している。薬学を基盤にデータサイエンスを学ぶ利点は, 実験(wet)と情報解析(in silico)の両方を理解できることにある。薬学はもともと創薬という共通の目標に向かって多様な専門家が協力する分野であり, 学際的な視点を自然に育む土壌がある。
ここで大切なのは, 単なる「データが扱える人」になることではない。薬学と情報科学の両方に強みを持つことで, これまでにない発見につながる研究ができる。我々は, そうした二つの分野を架橋する研究者を育てたいと考えている。
バイオインフォマティクスに挑戦したい, 薬学の知識を新しい形で活かしたい, 情報科学を研究に結びつけたいと思う方は, ぜひ気軽に連絡ください。研究はもちろん, 将来のキャリアについて一緒に考える場を提供します。